
Over the past week or so we've been testing Qwen-2.5-VL 7b as a Pulse Agent. We've had 36b and 72b parameter models fail basic testing so we weren't expecting much. Although Qwen's results aren't as long or as dense as those from ChatGPT or Claude it's still perfectly capable of using the system for retrieval and summary tasks:
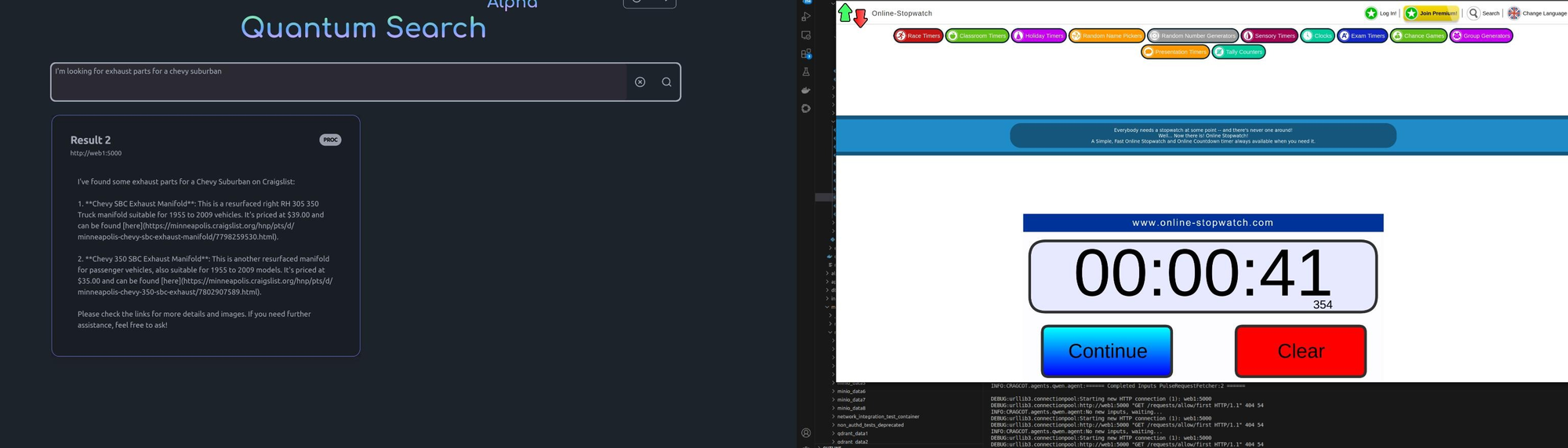
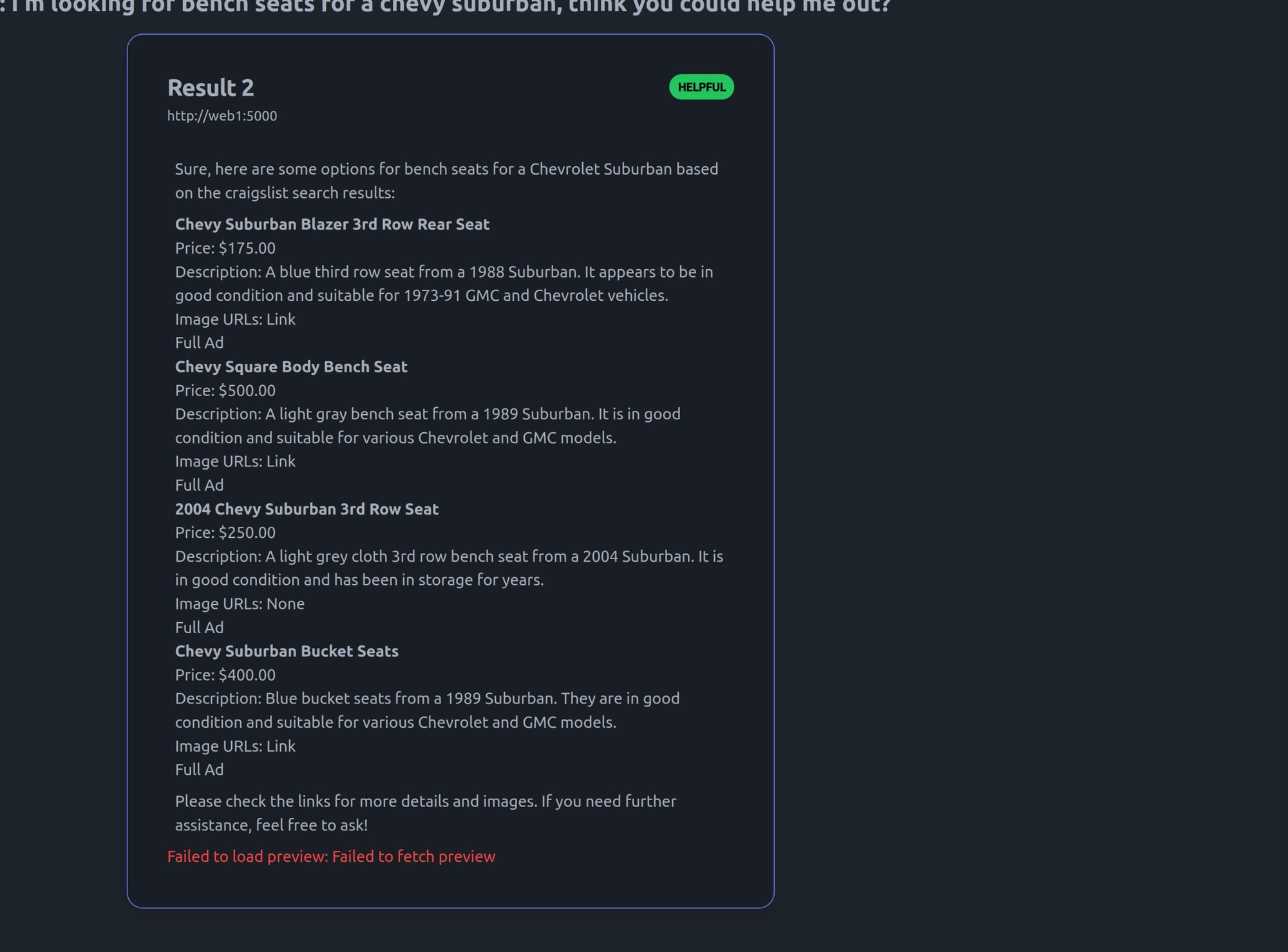
What's really special about this is that Qwen only uses about 18gb of vram at 16 bit quantization. This makes a single user node reasonable to host on consumer hardware like a 3090/4090 provided you have a decent CPU and at least 1-4gb of extra memory to support the rest of the stack. The bottom line is that Pulse is no longer dependant on cloud compute for personal/small business use cases.
We even had some limited (not quite production ready) success with automating backend interactions:

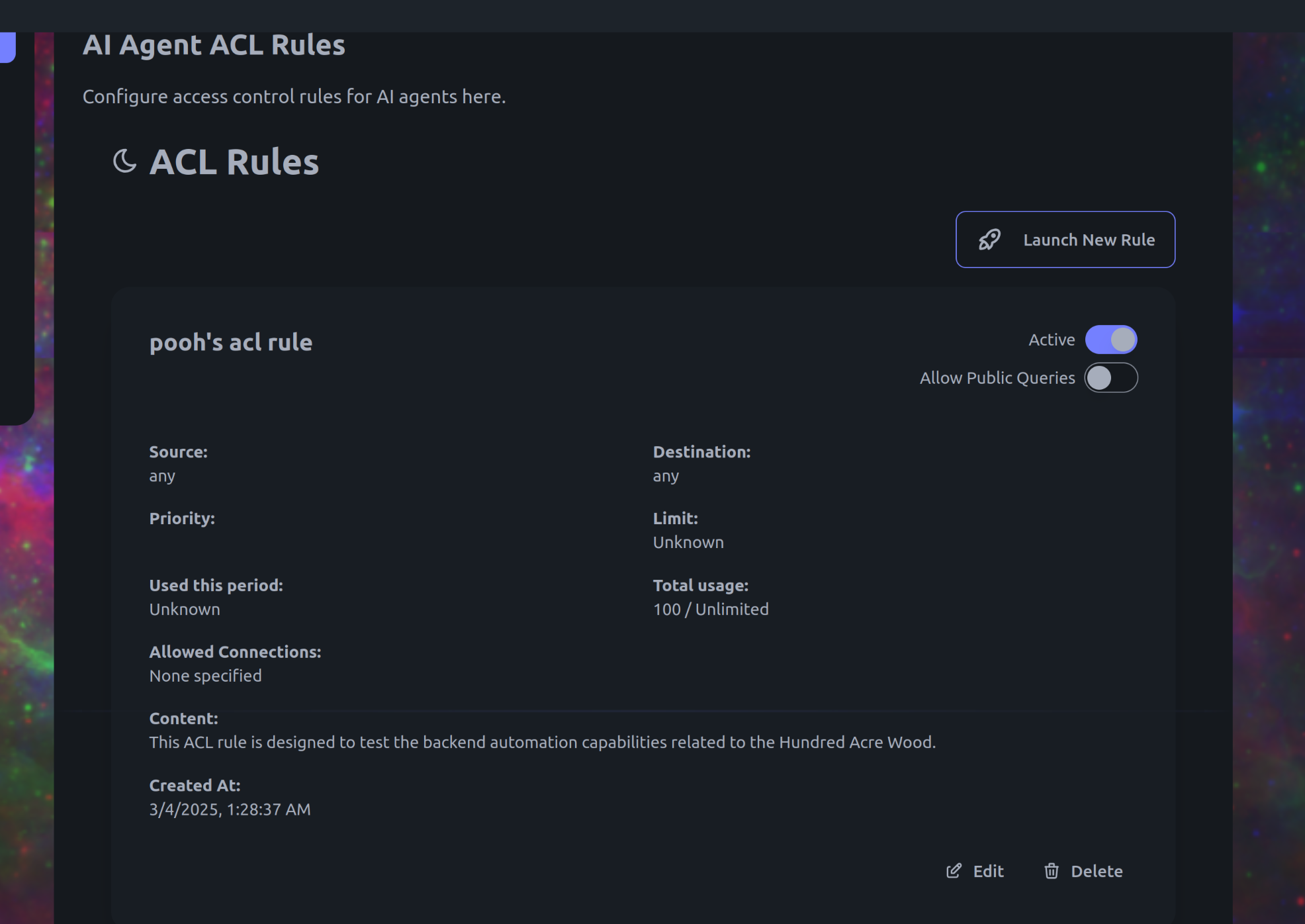
We're hoping for even better performance from the next release and will also begin working on a fine tuning dataset. More small model tests to come!

Member discussion: