Live In The Pod
Let's continue with our theme of technical updates followed by some medium-form interesting content about Pulse. The updates are an Android bugfix and a much-needed improved way to join/share Pods. Let's cover those and then talk about this week's topic: Orchestration vs Intelligence.
Technical Updates
- Fixed a longstanding/annoying bug in the Android version of Kash Stash that caused captions and Kash Files links to skip posting.
- New Pod Feature - Config Exports and Pod Links
- Clicking on a pod now reveals an extra button "export"
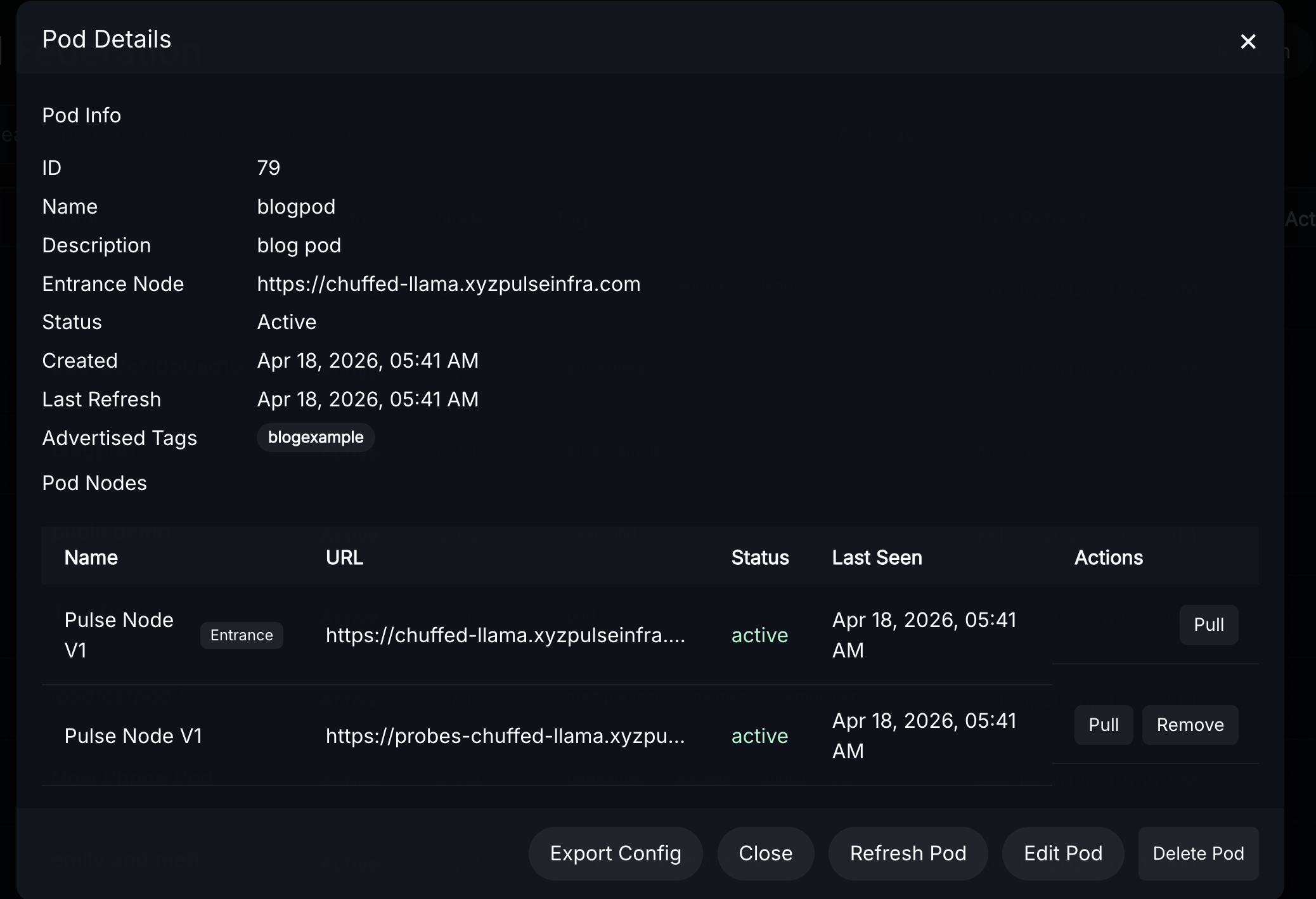
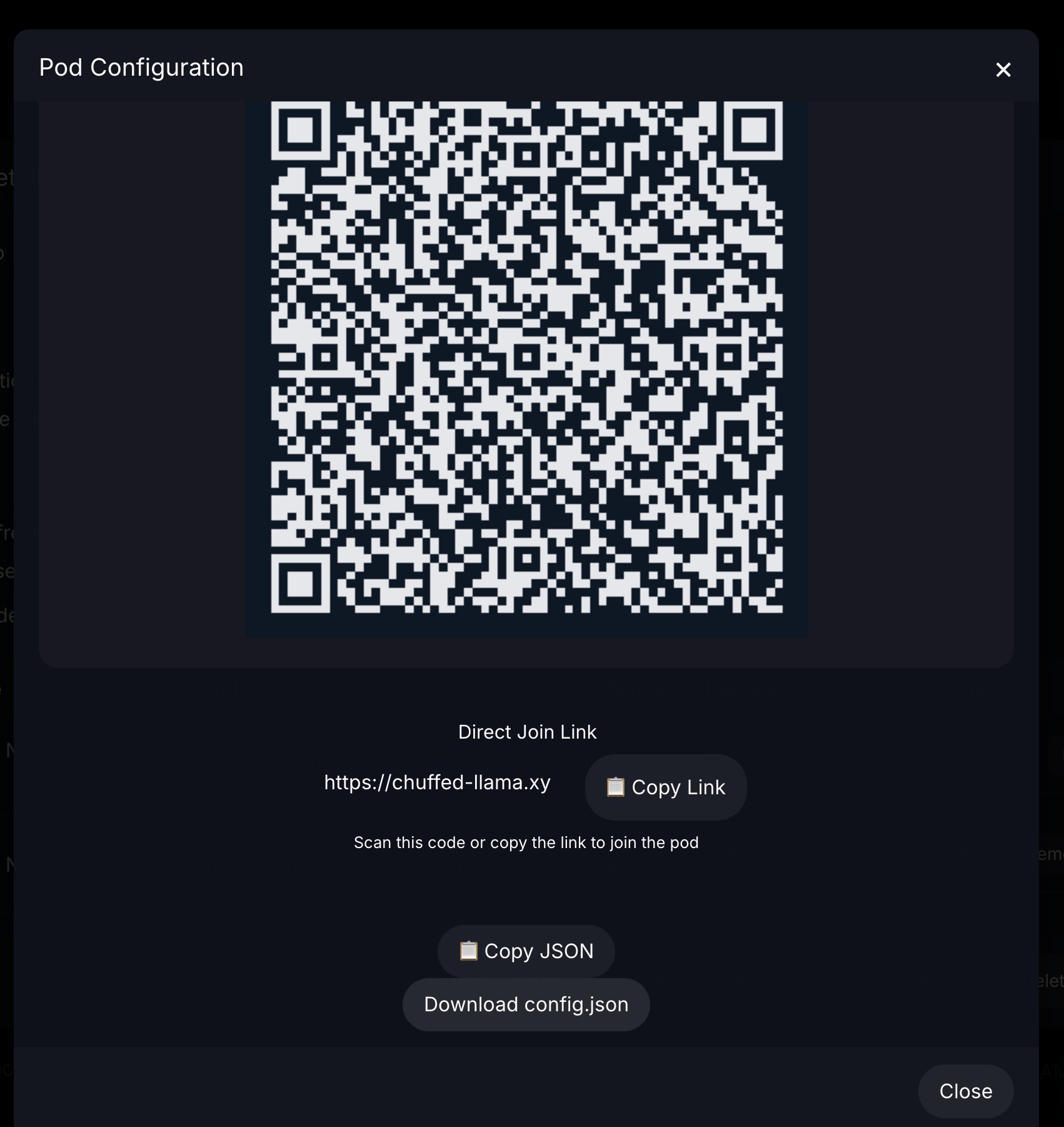
- Clicking it will display the new join link, json configuration string, downloadable json file, and a QR code that can all be used to configure a pod on the mobile app instead of manual entry
- There is now a corresponding import tab on the top-right corner of the page near "refresh" and "new pod" as well
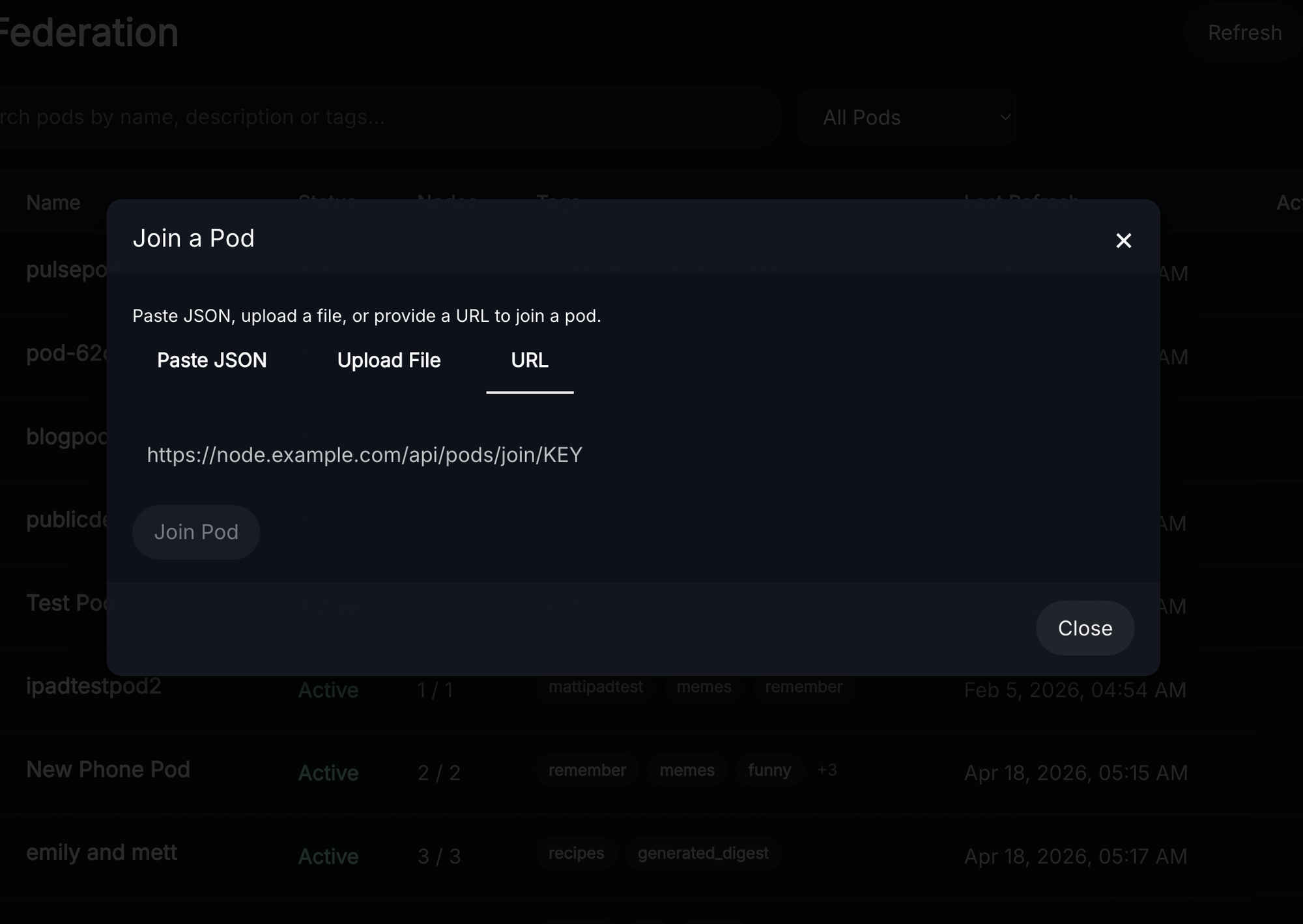
- this accepts the links/strings/json files produced by the export functionality and configures pods for you
Context in the Time of Leather Jackets
Jensen Huang, who we refer to as "Leather Jacket Man", made some comments recently that got us thinking about the state of AI. First, he said in several interviews that OpenClaw is "The Next Chatgpt." He's also been handing out glowing and sensible recommendations like spending up to $50k/year/engineer on Claude API Tokens.
Despite "Open" being in the name, OpenClaw generally doesn't work well with sub-foundation-level models. The system prompt alone is 20,000 tokens - almost as if the intent with OpenClaw was never to use it with open/locally hosted models. If I didn't know better I would say this is a tool for promoting Anthropic models, running on Nvidia hardware, to prosumers.
While I don't have concrete evidence this is marketing, I think it's obvious to anyone reading that the guy who sells enterprise graphics cards for AI would suggest that you have every engineer burning up to $50k/year in API credits that generate revenue for Nvidia's partners on his company's hardware.
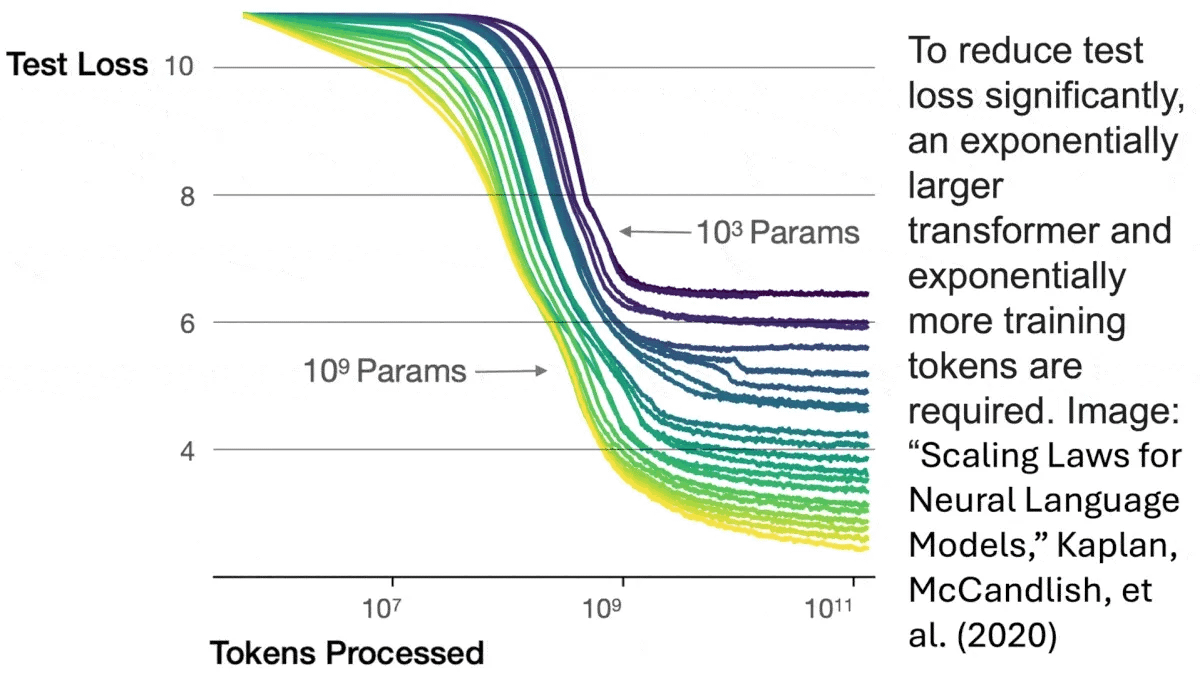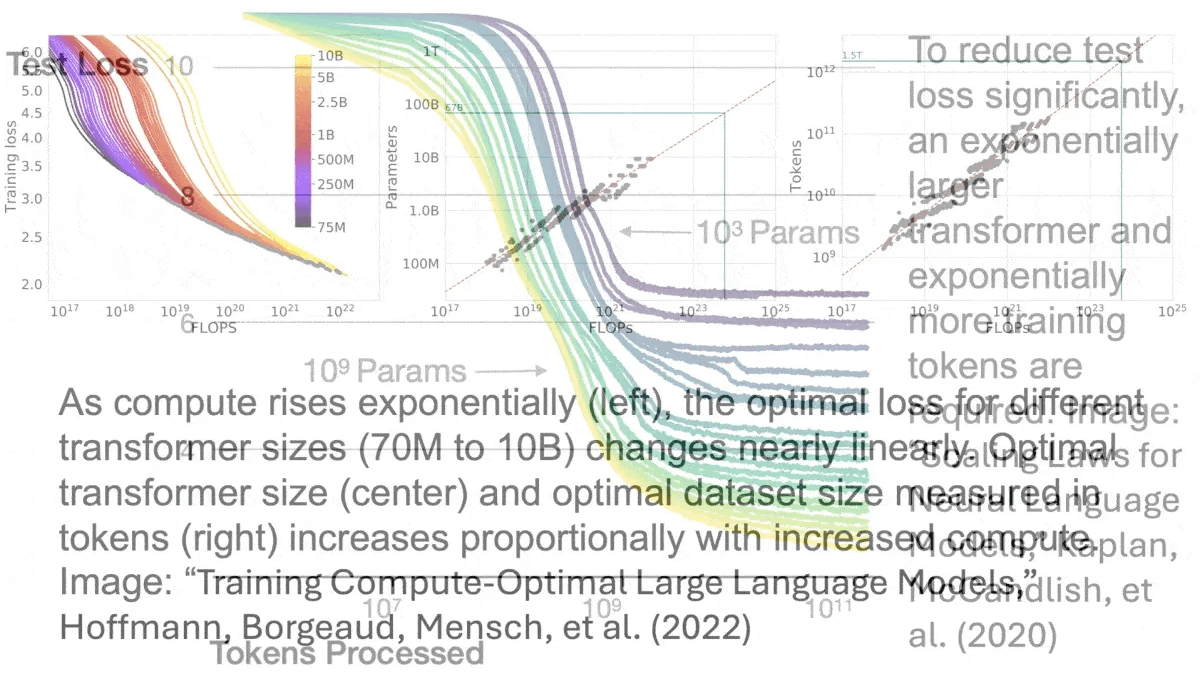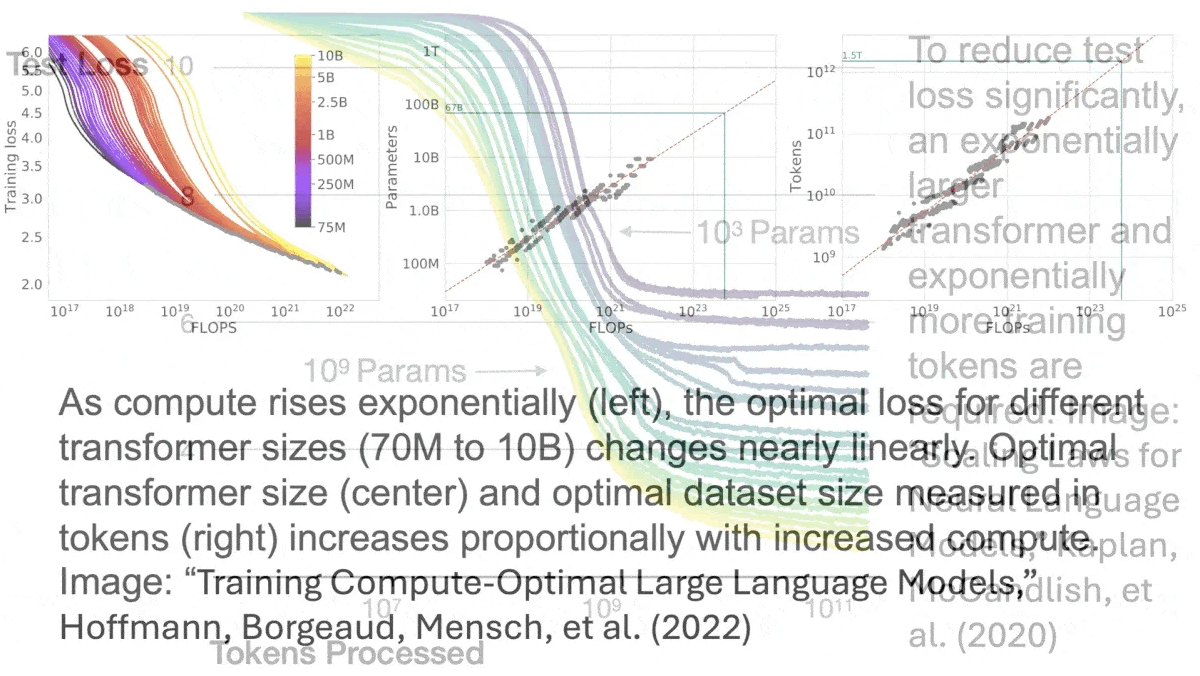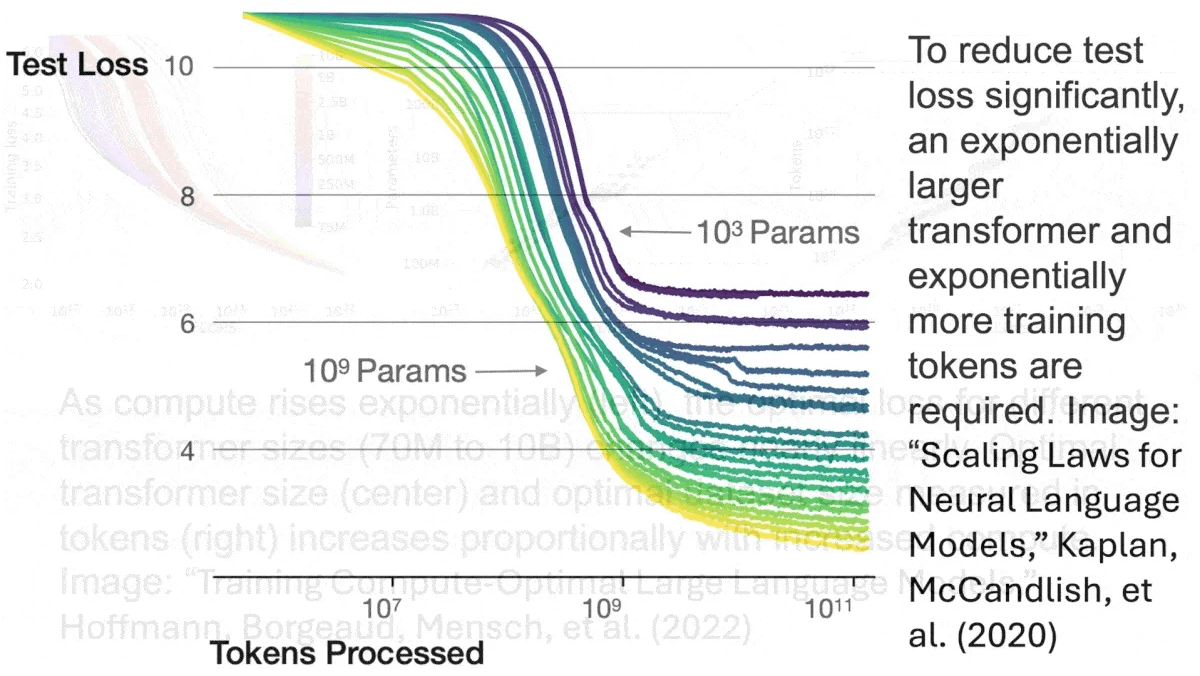
Primer on Scaling Laws
There are huge jumps in capability early on with LLMs, however, as you scale beyond ~30b parameters (in current frameworks) you start to run into diminishing returns that become very costly over time.
The first jump is basic reliable coherence in multi-turn conversations, like being able to discuss the weather without saying anything harmful or irrelevant. This occurs somewhere in the hundreds of millions of parameters, then there are two larger jumps in capability at reasonable scale.
The 7B Sweet Spot
7B is generally the line where reliable instruction following can happen in single-turn tasks, models at this size are capable of doing useful, repeatable work when given proper guardrails
The 30B Ceiling
30b is generally the line where complex tool calling capability for 1-3 turn tasks becomes reliable enough for real work (code, writing documents, etc)
Although they are more "expressive" and better at roleplaying 70b-120b parameter models frequently have real world performance that doesn't differ much from a 30b model in these tasks, the real advantage kicks in at 175b+ parameters, the next step above this isn't noticeable until you reach trillions of parameters.
What Does "Agent"/"Agentic" mean
An "agentic" AI uses its own reasoning abilities (usually following user-provided guidance) to plan its own course of action, this generally involves tool calling to other systems to store and retrieve information. True "agentic" frameworks like MCP are relatively loose with schema enforcement and require greater intelligence to operate/tend to produce inconsistent results/have the AI get "lost."
Why Does Pulse Call LLMs "Workers"
In Pulse, Workers are much smaller AI models that complete one portion of one task at a time using our workflow engine, which includes schema and grammar enforcement for each step. Steps can be inspected and retried, blending traditional "job pipelines" with AI and replacing traditional business logic. An "Agent" makes plans and decisions, a "Worker" completes a task.
Rather than relying on brittle "agentic reasoning" Pulse users compose workflows that can run in the background and produce consistently good results for deep research, etl, classification, and any other needs they meet through the workflow engine.
Why Does Orchestration Matter if a Foundation Model Can Do it Too?
The magic word here is "tokens per watt", and if there were a second magic word it would be "exotic hardware requirements." Serving foundation model inference requires nvlink or infiniband, enterprise grade GPUs with ECC memory and massive power requirements, and still results in generally poor token-per-watt metrics. By comparison, running a 7B VLLM and a 30a3b reasoning MoE on discarded mining GPUs and AVX512 CPUs respectively brings cost down to a level that enterprises can tolerate.
Because the strongest "jumps" in functionality occur at 7B and 30B and anything beyond that requires going to ~175B and then into the trillions of parameters complex tasks should probably be handled through a pipeline/workflow architecture rather than brute-force making LLMs larger/smarter to compensate for difficult reasoning chains or unusual/precise api schemas.
Are Agents Actually Good?
Agents are cool and they've gotten a lot of attention, but most frameworks are too brittle and too expensive to do the boring, repeatable work that actually runs a business. Workers aren't as flashy; but they show up every day, they don't get lost, and they run on hardware you can actually afford.

Member discussion: