Location
Click the "Upload" button in the top-right corner anywhere in the app to use the ingest tool.
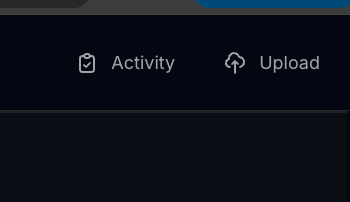
Layout
By default, the ingest tool will open to a file upload screen with options for tags, chunk size, context, and a file upload box.
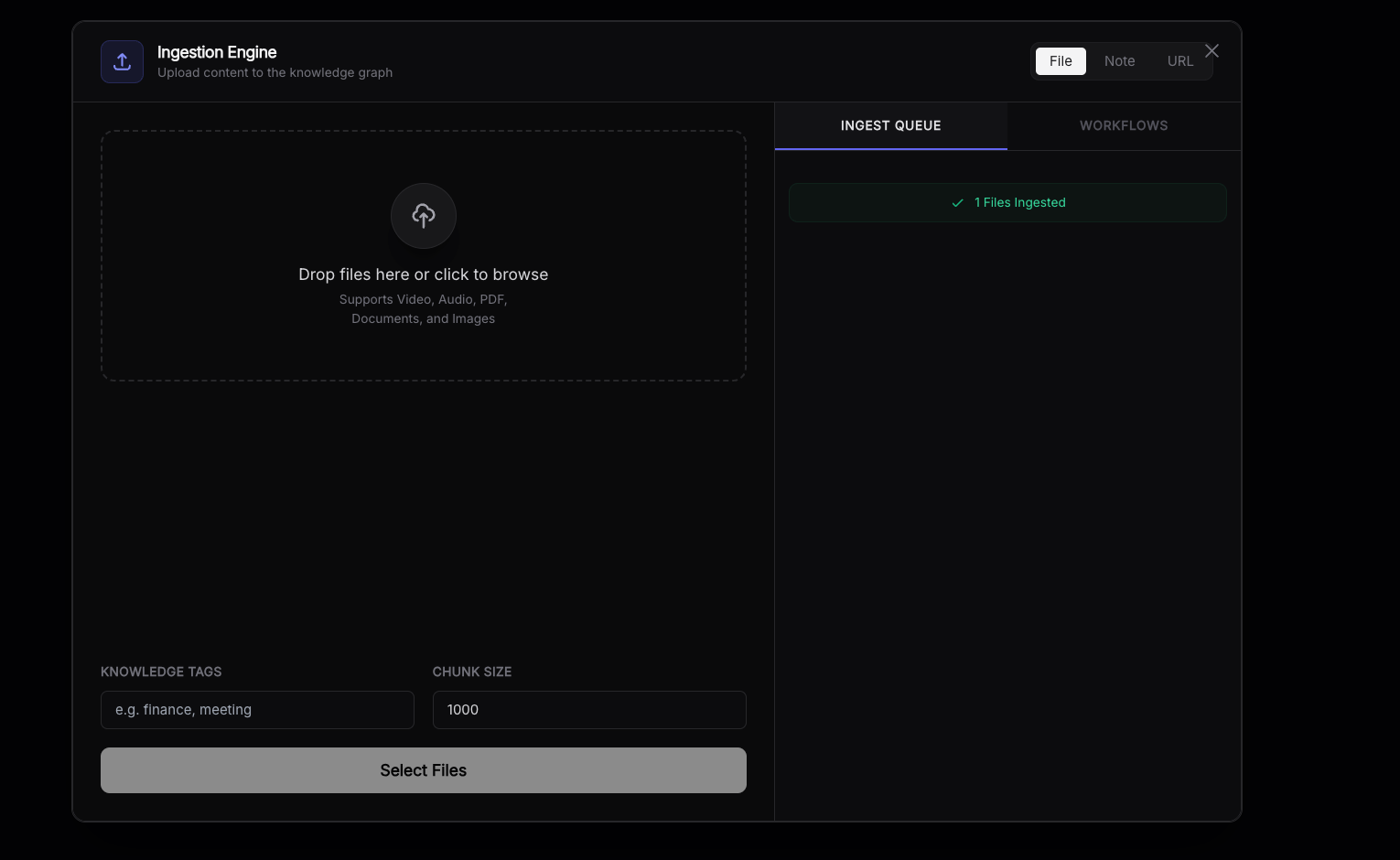
The righthand side shows the file/url ingestion queue status. You can also select the "note" option to ingest a quick note.
You can ingest from a URL using the "url" section.
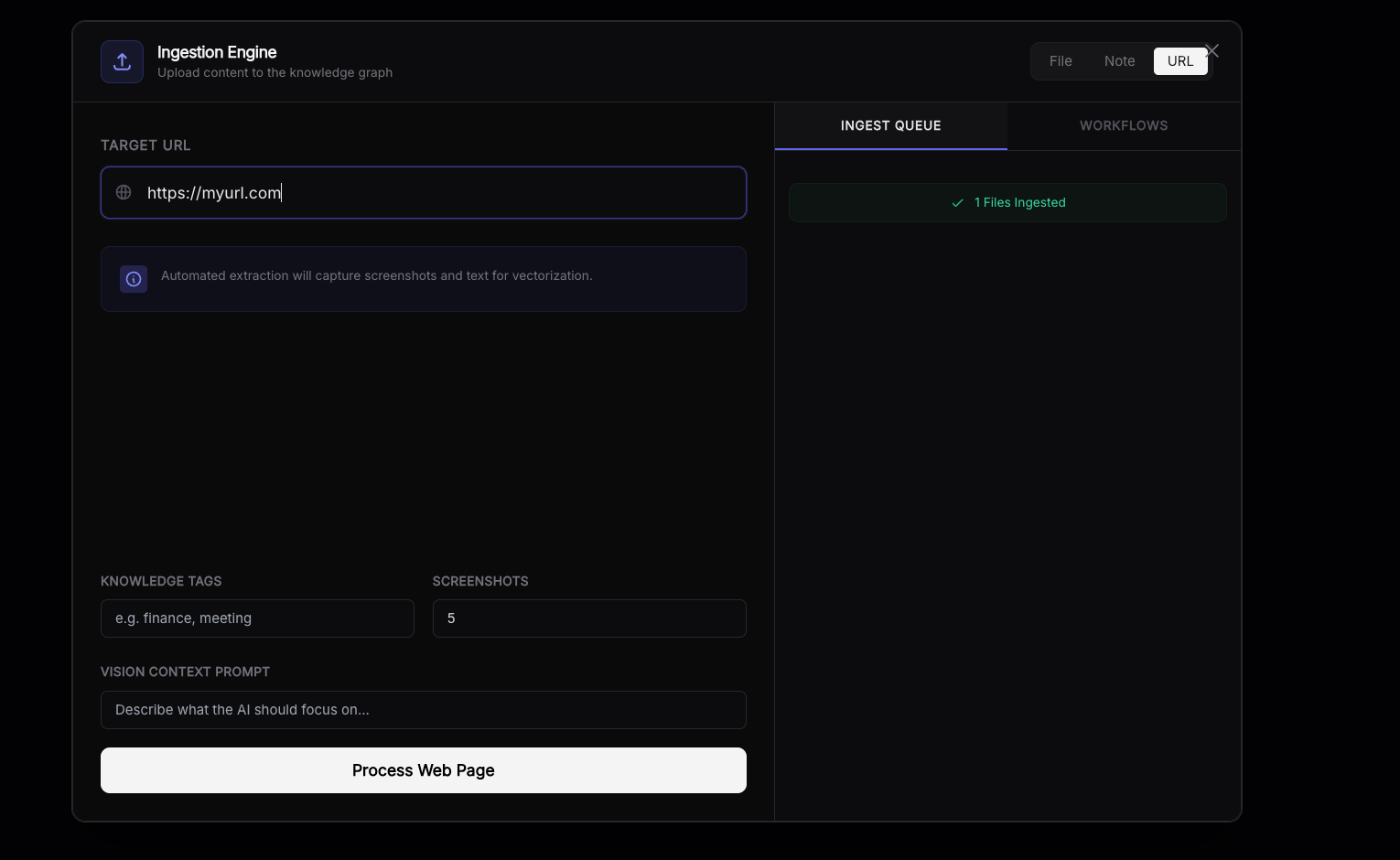
Content will be uploaded to the tags you configure with the chunk size you've selected.
Workflow Triggers
- If a workflow's settings match one or more of the tags used by ingestion the created digests will trigger workflows, be sure to check out the workflow documentation!
Videos
-
Videos can be ingested whole but keep in mind the ingesting agent is most likely only a 7B LLM with video understanding capabilities and smaller chunks will yield better understanding
-
Set the clip length to divide the video in to segments of that length
-
clip length can be thought of as the "resolution" you want to look at the video under
-
example 1: to get analysis of an intense soccer clip it would be best to keep clip length to around 20 seconds to make sure the AI captures all the information
-
example 2: if you're just looking at a podcast you may mostly want analysis of the audio context and submit the entire video as a single clip
-
The context prompt can be used to request structured output (ex: "count the number of people in the photos and output only peoplecount: N (newline) scenedescription: description")
Audio
- Audio files are ingested and transcribed whole with the resulting digests split by size in characters
Images
- Images can be transcribed with or without a context prompt
- If ingested without a context prompt the default prompt will instruct the ingesting agent to describe the image in a paragraph of text
- Context prompts can be used to gather specific information and structure output, this is very useful for quality control and customer service scenarios
- Example: "Please create structured entries with failure_mode: failure mode (newline) product_name: (newline) scene_description: scene description"
Documents and Web Pages
Simple documents
- RTF and TXT files are read directly into whole entries or into entries the length of the Chunk Size setting
- Word and ODF documents are currently ingested as text-only (graphs will not currently be "read" by the ingest tool)
PDFs
- Image Pdfs: Image PDFs are transcribed using OCR (an image recognition model is used to both transcribe the document and describe any figures) page by page chunked according to the chunk size parameter
- Text Pdfs: Text PDFs are read and chunked like simple documents
- "Image PDF Mode" is triggered when a PDF does not have a proportionately high amount of text defined in its data structure
Web Pages
- Web pages are printed as PDFs and transcribed the same way as above
Spreadsheets
- Spreadsheets are ingested such that each row becomes its own feed entry (while this may initially seem like it creates performance concerns our backend effectively runs off of a RAM Disk)
- Multiple worksheet ingestion is supported
- Ingestion of graphs/etc is not currently supported, but can be emulated by uploading screenshots of graphs if needed
Tag Selection
- Tags can be entered as a comma-separated list, all ingested content from that run will be placed under those tags